Using Apache Zeppelin with TIBCO ComputeDB
Do the following to use Apache Zeppelin with TIBCO ComputeDB:
- Download and Install TIBCO ComputeDB. The install zip for computeDB contains the Apache Zeppelin zip folder.
- Configure the TIBCO ComputeDB Cluster.
-
Unzip the Apache Zeppelin artifact zeppelin-0.8.2-snappydata-1.2.0.zip. Change to the directory zeppelin-0.8.2-snappydata-1.2.0 and start Apache Zeppelin server.
$ unzip zeppelin-0.8.2-snappydata-1.2.0.zip $ cd zeppelin-0.8.2-snappydata-1.2.0/ $ ./bin/zeppelin-daemon.sh start -
Enter this URL in the browser: localhost:8080 or (AWS-AMI_PublicIP):8080.
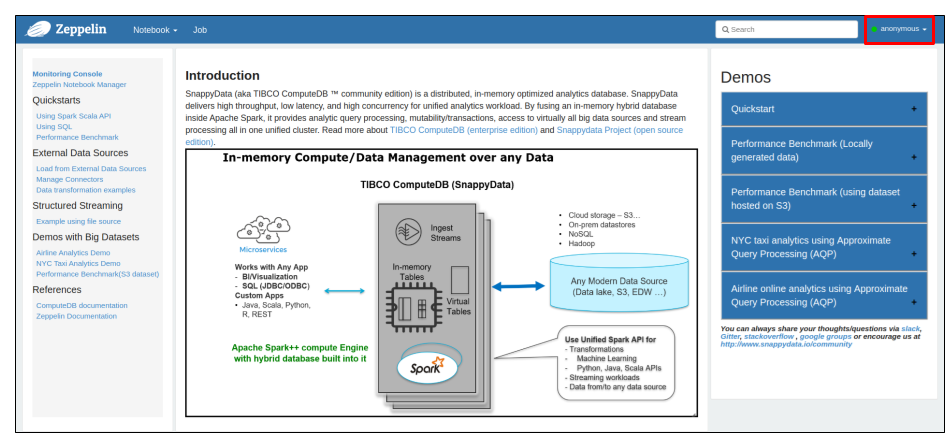
Refer here for instructions to configure Apache Zeppelin for securely accessing TIBCO ComputeDB Cluster.
FAQs
-
I am on the homepage, what should I do next?
- If you are using TIBCO ComputeDB for the first time, you can start with the QuickStart notebooks to start exploring the capabilities of the product.
- If you have used TIBCO ComputeDB earlier and just want to explore the new interface, you can download data from external sources using the notebooks in the External Data Sources section.
-
I get an error when I run a paragraph?
- By design, the anonymous user is not allowed to execute notebooks.
- You may clone the notebook and proceed in the cloned notebook.
-
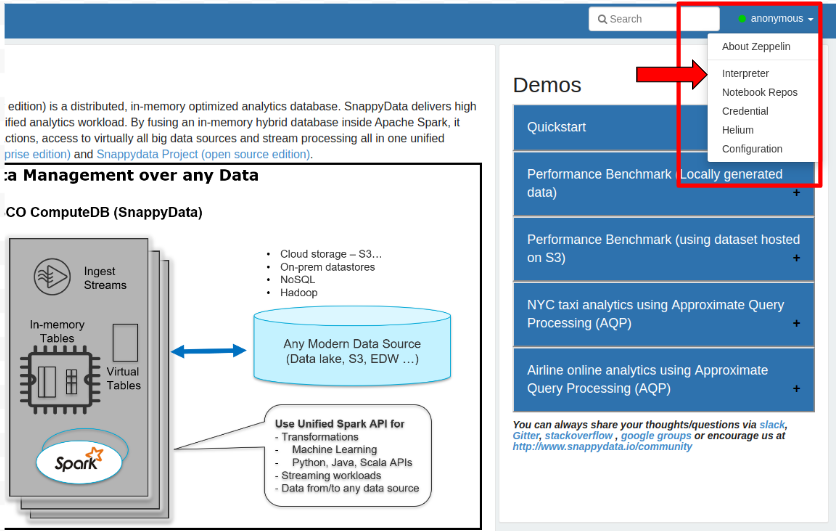
Do I need to change any setting in Zeppelin to work with the multi-node cluster?
- Yes, but this requires Zeppelin’s admin user access. By default, you access the Zeppelin notebooks as an anonymous user. For admin user access, click the Interpreter tab and enter your credentials in the Login box. You can find the admin credentials in the zeppelin-dir/conf/shiro.ini file.
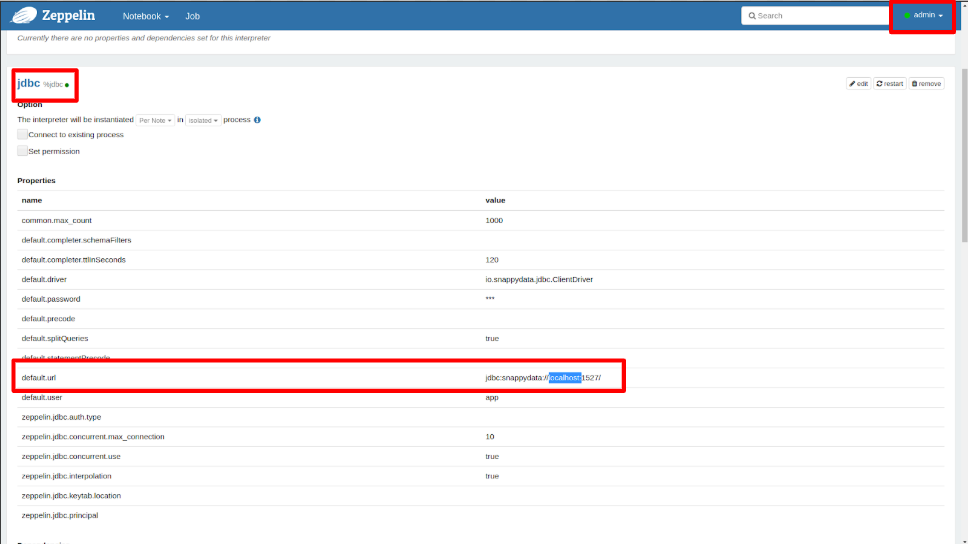
- Update the appropriate IP of a server node in the jdbc URL (highlighted in the following image).
- Yes, but this requires Zeppelin’s admin user access. By default, you access the Zeppelin notebooks as an anonymous user. For admin user access, click the Interpreter tab and enter your credentials in the Login box. You can find the admin credentials in the zeppelin-dir/conf/shiro.ini file.
-
I already have a Zeppelin installation, do I still need to install TIBCO ComputeDB’s Zeppelin separately?
- No. You may download the notebooks from here and import them into your Zeppelin.
- Additionally, you must set up the JDBC interpreter to connect to TIBCO ComputeDB. Configure JDBC Interpreter.
-
Do these notebooks depend on specific Zeppelin version? Yes, these notebooks were developed on Zeppelin version 0.8.2.
-
Are there any configuration files of Zeppelin that I need to be aware of? For advanced multi-user settings, refer to the zeppelin-site.xml and shiro.ini. For more details and options, refer to the Apache Zeppelin documentation.
-
Is Zeppelin the only interface to interact with TIBCO ComputeDB? No, if you prefer a command-line interface, then the product provides two command-line interfaces. The SQL interface, which can be accessed using ./bin/snappy and the experimental scala interpreter can be invoked using ./bin/snappy-scala.
-
How to configure Apache Zeppelin to securely and concurrently access the TIBCO ComputeDB Cluster? Refer to How to Configure Apache Zeppelin to Securely and Concurrently access the TIBCO ComputeDB Cluster.